TDAlgorithms_IEEE24
parents
Showing
.gitignore
0 → 100644
This diff is collapsed.
Click to expand it.
Algorithms/ABTD.py
0 → 100644
Algorithms/BaseGradient.py
0 → 100644
Algorithms/BaseLS.py
0 → 100644
Algorithms/BaseTD.py
0 → 100644
Algorithms/BaseVariableLmbda.py
0 → 100644
Algorithms/ETD.py
0 → 100644
Algorithms/ETDLB.py
0 → 100644
Algorithms/GEMETD.py
0 → 100644
Algorithms/GTD.py
0 → 100644
Algorithms/GTD2.py
0 → 100644
Algorithms/HTD.py
0 → 100644
Algorithms/LSETD.py
0 → 100644
Algorithms/LSTD.py
0 → 100644
Algorithms/PGTD2.py
0 → 100644
Algorithms/TB.py
0 → 100644
Algorithms/TD.py
0 → 100644
Algorithms/TDRC.py
0 → 100644
Algorithms/Vtrace.py
0 → 100644
Assets/Emphatics_sensitivity.png
0 → 100644
{kind=link}
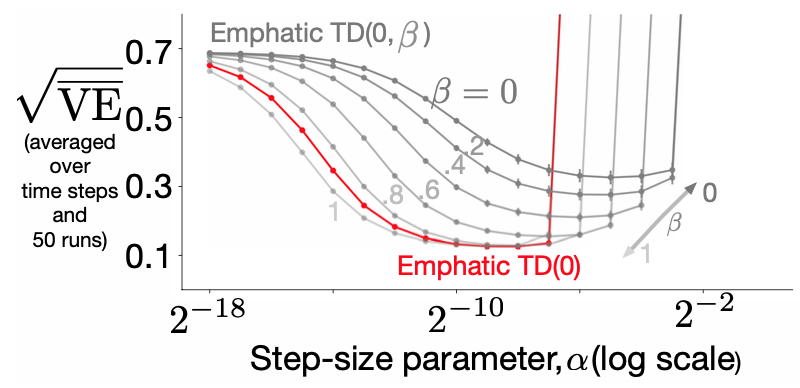
104 KB
Assets/FourRoomGridWorld.gif
0 → 100644
{kind=link}
396 KB
Assets/Gradients_sensitivity.png
0 → 100644
{kind=link}
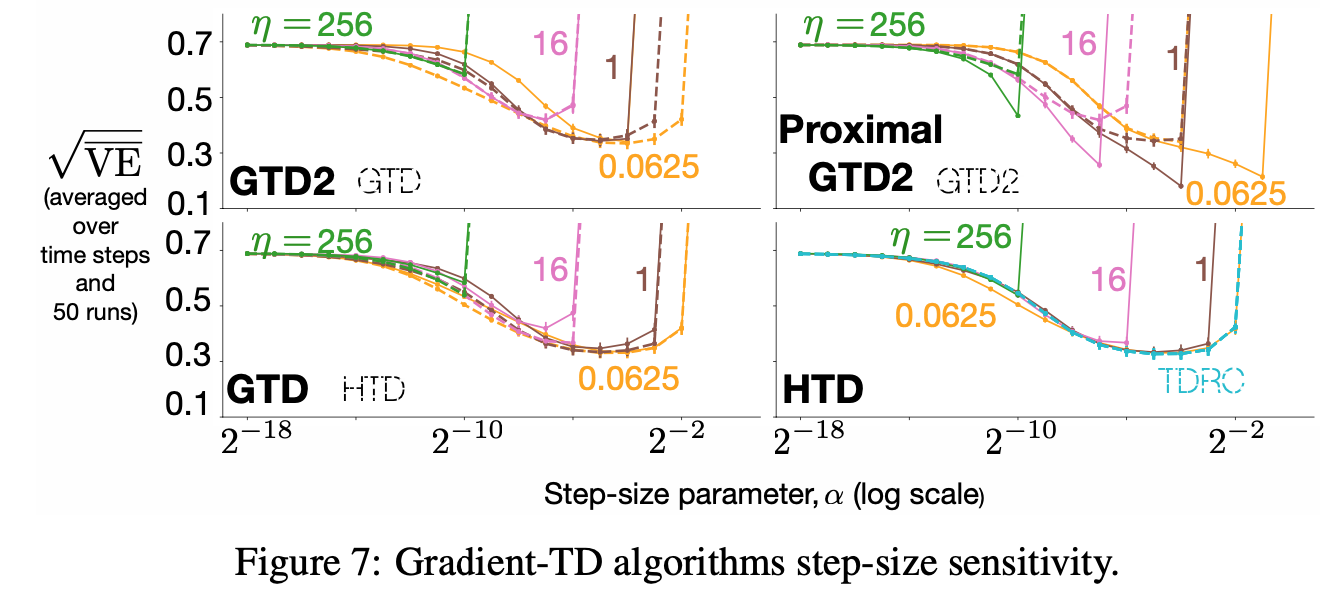
196 KB
Assets/chain.gif
0 → 100644
{kind=link}

3.26 KB
Assets/eight_state_collision.png
0 → 100644
{kind=link}

73.7 KB
Assets/learning_curves.png
0 → 100644
{kind=link}
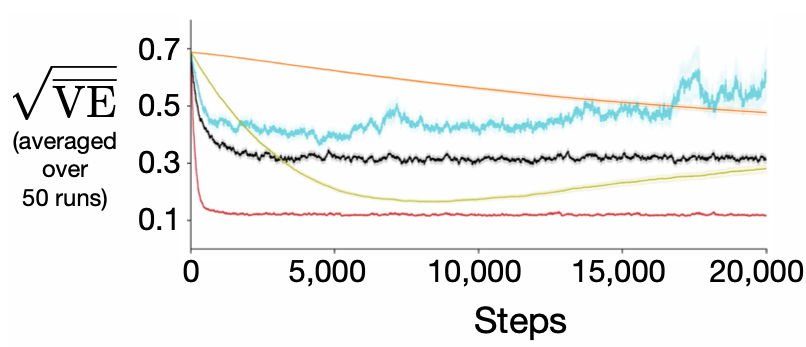
117 KB
Assets/parameters.png
0 → 100644
{kind=link}
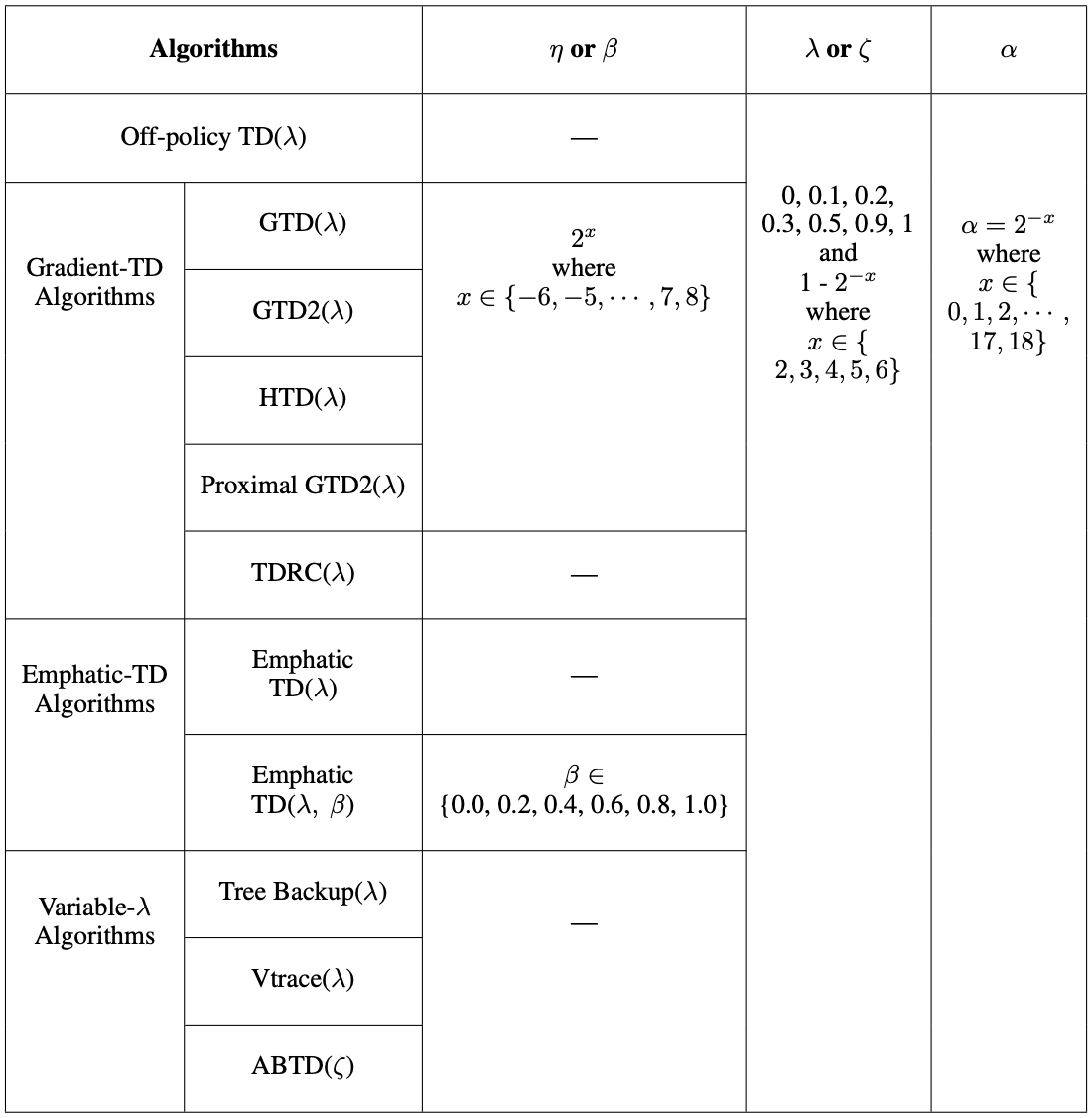
122 KB
Assets/plots.png
0 → 100644
{kind=link}
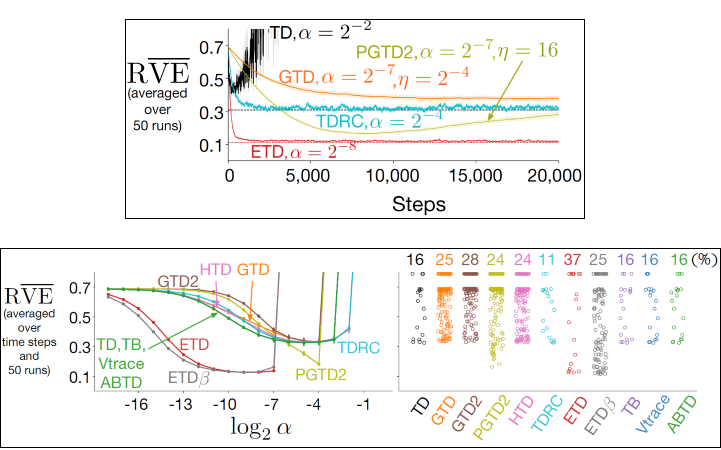
115 KB
Assets/rlai.png
0 → 100644
{kind=link}

81.1 KB
Assets/sensitivity_curves_of_all_algs.png
0 → 100644
{kind=link}
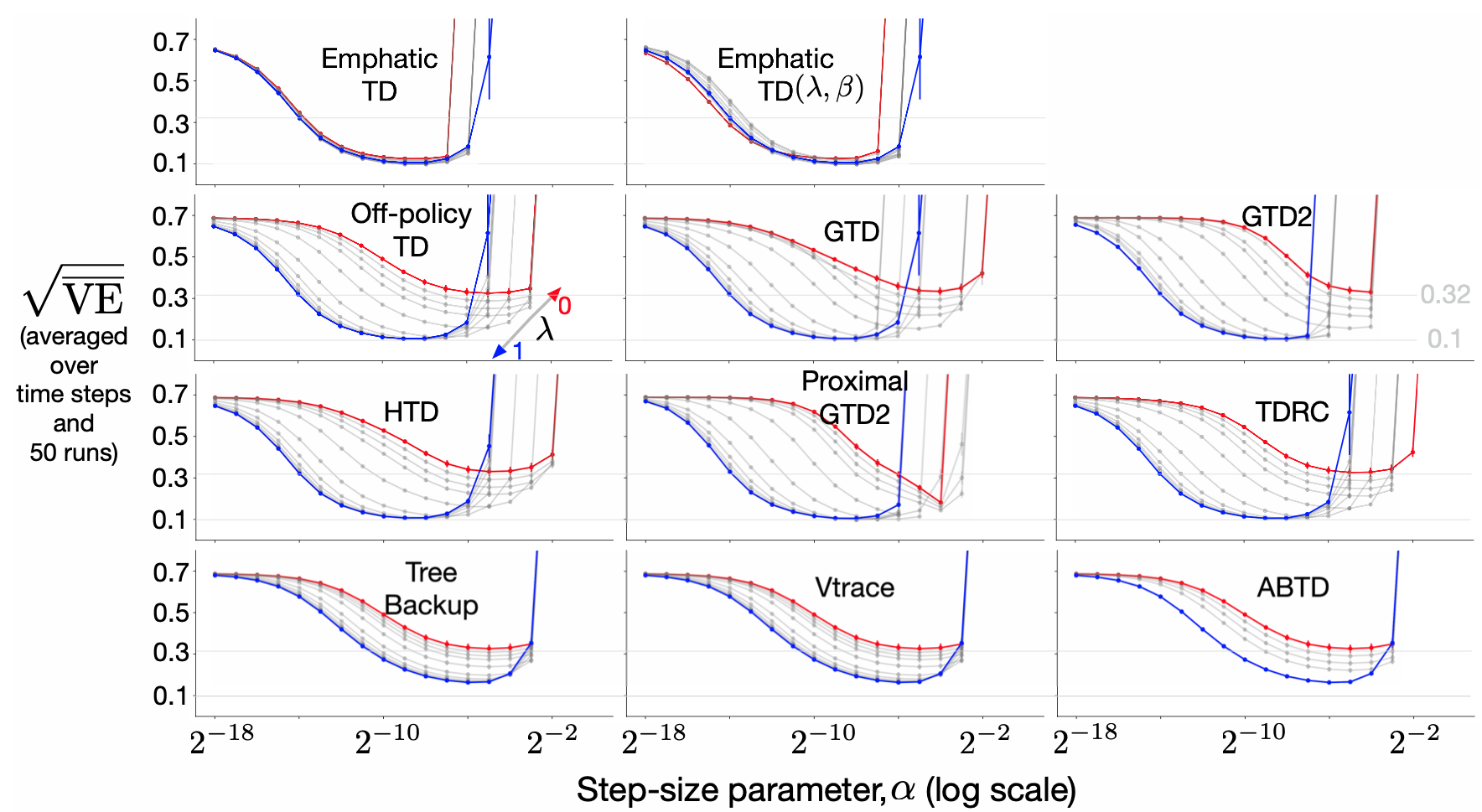
572 KB
Assets/specific_learning_curves.png
0 → 100644
{kind=link}
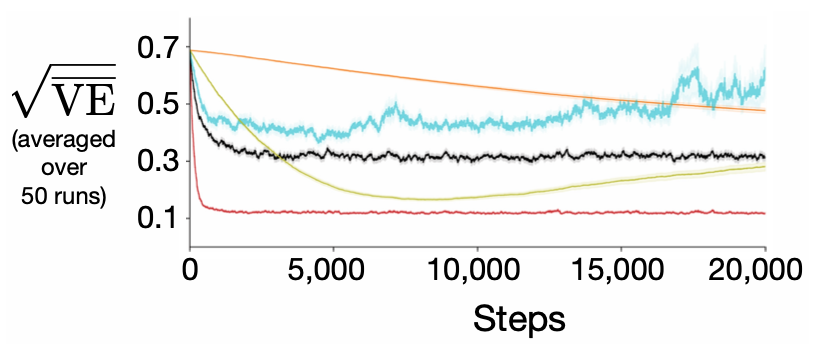
118 KB
Assets/value_functions.png
0 → 100644
{kind=link}

163 KB
Environments/Chain.py
0 → 100644
Environments/FourRoomGridWorld.py
0 → 100644
Environments/rendering.py
0 → 100644
Environments/utils.py
0 → 100644
Experiments/1HVFourRoom/ABTD/ABTD.json
0 → 100644
Experiments/1HVFourRoom/ETD/ETD.json
0 → 100644
Experiments/1HVFourRoom/ETDLB/ETDLB.json
0 → 100644
Experiments/1HVFourRoom/GTD/GTD.json
0 → 100644
Experiments/1HVFourRoom/GTD2/GTD2.json
0 → 100644
Experiments/1HVFourRoom/HTD/HTD.json
0 → 100644
Experiments/1HVFourRoom/PGTD2/PGTD2.json
0 → 100644
Experiments/1HVFourRoom/TB/TB.json
0 → 100644
Experiments/1HVFourRoom/TD/TD.json
0 → 100644
Experiments/1HVFourRoom/TDRC/TDRC.json
0 → 100644
Experiments/1HVFourRoom/Vtrace/Vtrace.json
0 → 100644
Experiments/FirstChain/ABTD/ABTD.json
0 → 100644
Experiments/FirstChain/ETD/ETD.json
0 → 100644
Experiments/FirstChain/ETDLB/ETDLB.json
0 → 100644
Experiments/FirstChain/GTD/GTD.json
0 → 100644
Experiments/FirstChain/GTD2/GTD2.json
0 → 100644
Experiments/FirstChain/HTD/HTD.json
0 → 100644
Experiments/FirstChain/PGTD2/PGTD2.json
0 → 100644
Experiments/FirstChain/TB/TB.json
0 → 100644
Experiments/FirstChain/TD/TD.json
0 → 100644
Experiments/FirstChain/TDRC/TDRC.json
0 → 100644
Experiments/FirstChain/Vtrace/Vtrace.json
0 → 100644
Experiments/FirstFourRoom/ABTD/ABTD.json
0 → 100644
Experiments/FirstFourRoom/ETD/ETD.json
0 → 100644
Experiments/FirstFourRoom/ETDLB/ETDLB.json
0 → 100644
Experiments/FirstFourRoom/GTD/GTD.json
0 → 100644
Experiments/FirstFourRoom/GTD2/GTD2.json
0 → 100644
Experiments/FirstFourRoom/HTD/HTD.json
0 → 100644
Experiments/FirstFourRoom/PGTD2/PGTD2.json
0 → 100644
Experiments/FirstFourRoom/TB/TB.json
0 → 100644
Experiments/FirstFourRoom/TD/TD.json
0 → 100644
Experiments/FirstFourRoom/TDRC/TDRC.json
0 → 100644
Experiments/FirstFourRoom/Vtrace/Vtrace.json
0 → 100644
ExportBin/ReadMe
0 → 100644
Job/Cedar_Create_Config_Template.sh
0 → 100644
Job/JobBuilder.py
0 → 100644
Job/SubmitJobsTemplates.SL
0 → 100644
Job/SubmitJobsTemplatesCedar.SL
0 → 100644
Learning.py
0 → 100644
Plotting/plot_dist.py
0 → 100644
Plotting/plot_learning_curve.py
0 → 100644
Plotting/plot_learning_for_two_lambdas.py
0 → 100644
Plotting/plot_params.py
0 → 100644
Plotting/plot_sensitivity.py
0 → 100644
Plotting/plot_sensitivity_for_two_lambdas.py
0 → 100644
Plotting/plot_specific_learning_curves.py
0 → 100644
Plotting/plot_utils.py
0 → 100644
Plotting/plot_waterfall.py
0 → 100644
Plotting/process_state_value_function.py
0 → 100644
README.md
0 → 100644
This diff is collapsed.
Click to expand it.
Registry/AlgRegistry.py
0 → 100644
Registry/EnvRegistry.py
0 → 100644
Registry/TaskRegistry.py
0 → 100644
Resources/EightStateCollision/d_mu.npy
0 → 100644
File added
File added
File added
File added
File added
File added
File added
This diff is collapsed.
Click to expand it.
This diff is collapsed.
Click to expand it.
Tasks/BaseTask.py
0 → 100644
This diff is collapsed.
Click to expand it.
Tasks/EightStateCollision.py
0 → 100644
This diff is collapsed.
Click to expand it.
This diff is collapsed.
Click to expand it.
Tasks/LearnEightPoliciesTileCodingFeat.py
0 → 100644
This diff is collapsed.
Click to expand it.
Tests/Algorithms/TestTD.py
0 → 100644
This diff is collapsed.
Click to expand it.
Tests/Environments/TestChain.py
0 → 100644
This diff is collapsed.
Click to expand it.
Tests/Tasks/TestEightStateCollision.py
0 → 100644
This diff is collapsed.
Click to expand it.
data_presister.py
0 → 100644
This diff is collapsed.
Click to expand it.
main.py
0 → 100644
This diff is collapsed.
Click to expand it.
plot_data.py
0 → 100644
This diff is collapsed.
Click to expand it.
process_data.py
0 → 100644
This diff is collapsed.
Click to expand it.
requirements.txt
0 → 100644
This diff is collapsed.
Click to expand it.
test.py
0 → 100644
This diff is collapsed.
Click to expand it.
unittest_suite.py
0 → 100644
This diff is collapsed.
Click to expand it.
utils.py
0 → 100644
This diff is collapsed.
Click to expand it.